SQL의 장단점
<장점>
- 사용자가 이해하기 쉬운 단어로 구성되어 있다.
- 쉽게 배울 수 있다.
- 복잡한 로직을 간단하게 작성할 수 있다.
- ANSI에 의해 문법이 표준화되어 있다.
<단점>
- 반복처리를 할 수 없다. (LOOP)
- 비교처리를 할 수 없다. (IF)
- Error처리를 할 수 없다. (Exception)
- SQL문을 캡슐화할 수 없다.
- 변수선언을 할 수 없다.
- 실행할 때마다 분석작업 후 실행해야 한다.
- Network Traffic을 유발한다.
이러한 단점을 극복하기 위해 PL/SQL을 사용한다. PL/SQL은 SQL로 얻을 수 없는 절차적 언어의 기능을 가지고 있다.
※ PL/SQL: Oracle's Procedural Language extension to SQL
PL/SQL의 기초
PL/SQL 사용 이유
- 반복처리를 할 수 있다. (LOOP)
- 비교처리를 할 수 있다. (IF)
- Error처리를 할 수 있다. (Exception)
- SQL문을 캡슐화할 수 있다. - 데이터의 보안 및 무결성
- 변수선언을 할 수 있다.
- 실행할 때마다 분석된 결과를 실행만 하기 때문에 성능이 빠르다.
- Network Traffic이 감소된다. - 여러 SQL문장을 block으로 묶고 블럭 전부를 한번에 서버로 전송하기 때문에 통신량을 줄일 수 있다.
PL/SQL의 처리
PL/SQL로 작성된 블럭을 오라클 서버로 보내면 그 안에 있는 PL/SQL 엔진이 sql문과 non-sql문을 구분하여
non-sql문은 PL/SQL 엔진 내의 Procedural statement executor가 수행하고, sql문은 SQL statement executor가 처리하게 된다. 즉, non-sql문은 client환경에서 처리되고 sql문은 서버에서 실행하게 된다.
따라서 PL/SQL을 사용하게 되면 서버쪽에서의 작업량이 줄게되므로 성능을 향상시킬 수 있는 이점이 있다.
PL/SQL Block
PL/SQL Block의 구조
선언부(선택적)
실행부(필수적)
예외처리부(선택적)
PL/SQL Block의 유형
1. 익명 블럭(Anonymous Block)
[DECLARE]
BEGIN
실행문장;
실행문장;
[EXCEPTION]
END;
- 이름 없는 블럭을 의미한다. 실행하기 위해 프로그램 안에서 선언되고 실행을 위해 PL/SQL 엔진으로 전달된다. 선행 컴파일러 프로그램과 Sql plus 또는 서버 관리자에서 익명의 블럭을 내장할 수 있다.
- 선언부(Declare): PL/QSL에서 사용하는 변수나 상수를 선언하는 부분 (옵션)
- 실행부(Begin): SQL문을 실행할 수 있도록 절차적 언어요소인 제어문, 반복문, 함수 정의 등 로직을 기술하는 부분 (필수)
- 예외처리부(Exception): 예외를 처리하기 위한 문장을 기술하는 부분 (옵션)
2. 서브프로그램(Subprogram)
| 프로시저(Procedure) | 함수(Function) |
| CREATE [OR REPLACE] PROCEDURE 프로시저명( 변수 선언 ) IS BEGIN 실행문장; 실행문장; ... [EXCEPTION] END; / |
CREATE [OR REPLACE] FUNCTION 함수명(인파라미터) RETURN datatype IS BEGIN 실행문장; 실행문장; ... RETURN value; [EXCEPTION] END; / |
Subprogram은 매개변수를 사용할 수 있고 호출할 수 있는 PL/SQL 블럭이다.
프로시저 or 함수로 선언될 수 있는데, 어떤 작업을 수행하기 위해서는 프로시저를 사용하고, 값을 계산하기 위해서는 함수를 사용한다.
프로시저(Procedure)
프로시저(Procedure) 정의
- 넓은 의미는 어떤 업무를 처리하기 위한 절차
- 결과값 반환 없이 특정 로직을 처리
- 질의의 집합으로 어떤 동작을 일괄 처리
- 테이블에서 데이터 추출 및 조작, 결과를 다른 테이블에 저장하거나 갱신
프로시저 문법
CREATE [OR REPLACE] PROCEDURE 프로시저명(
매개변수명1 [ IN | OUT | IN OUT ] 데이터 타입,
매개변수명2 [ IN | OUT | IN OUT ] 데이터 타입, ...
)
IS | AS
변수 및 상수 선언
BEGIN
실행 문장
EXCEPTION
WHEN 예외1(사전 정의된 오류 or 사용자 정의 오류) THEN
statement1...
WHEN 예외2(사전 정의된 오류 or 사용자 정의 오류) THEN
statement2...
WHEN OTHERS THEN
statement3...
END;
/
서버 출력 허용
SET SERVEROUTPUT ON;기본적으로 PL/SQL은 결과물을 보여주지 않는다.
결과물을 보고 싶다면 SERVEROUTPUT 설정을 ON으로 설정해야 한다. (default: OFF)
프로시저 실행
EXECUTE 프로시저명();EXEC 프로시저명();
프로시저(Procedure) 실습
[1] 익명블럭으로 프로시저 생성
SET SERVEROUTPUT ON;
DECLARE
--선언부
i_msg VARCHAR2(100);
today TIMESTAMP;
BEGIN
--실행부
i_msg := 'Hello World'; -- := 대입연산자 (변수에 값 할당)
SELECT SYSTIMESTAMP INTO today FROM dual; --today 변수에 SYSTIMESTAMP를 넣어 줌
--변수값 출력
dbms_output.put_line(i_msg);
dbms_output.put_line(today);
END;
/
--[실습] 현재 시간에서 1시간 전과 3시간 후의 시각을 구해 출력하는 프로시저를 작성하세요
DECLARE
time_1 TIMESTAMP;
time_3 TIMESTAMP;
BEGIN
SELECT SYSTIMESTAMP-1/24 INTO time_1 FROM dual;
SELECT SYSTIMESTAMP+3/24 INTO time_3 FROM dual;
dbms_output.put_line('1시간 전: ' || time_1);
dbms_output.put_line('3시간 후: ' || time_3);
END;
/
[2] 이름을 갖는 프로시저 생성
--java_member 테이블에 데이터를 삽입하는 프로시저를 작성하세요
--id, pw, name, tel => in parameter
CREATE OR REPLACE PROCEDURE java_member_add(
p_id IN VARCHAR2,
p_pw IN VARCHAR2,
p_name IN VARCHAR2,
p_tel IN VARCHAR2
)
IS
BEGIN
INSERT INTO java_member (id, pw, name, tel)
VALUES(p_id, p_pw, p_name, p_tel);
COMMIT;
dbms_output.put_line(p_name || '님의 정보를 등록했어요');
--예외처리
EXCEPTION
WHEN dup_val_on_index THEN
dbms_output.put_line(p_id || '는 이미 존재하는 아이디입니다. 등록 실패!');
END;
/
----------------------------------------------------------------------------
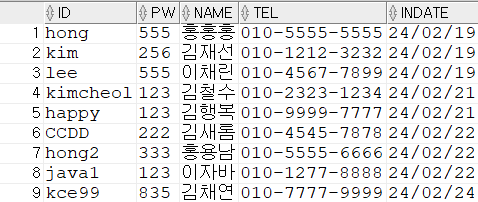
EXEC java_member_add('kce99', '835', '김채연', '010-7777-9999'); --등록 완료
SELECT * FROM java_member;
EXEC java_member_add('hong', '835', '홍길떵', '010-7777-9999'); --등록 실패(이미 존재)

--[실습] emp에서 부서번호와 인상율(10%, 20%...)을 인파라미터로 받아서
--해당 부서의 사원들의 급여를 인상률만큼 인상하는 프로시저를 작성하세요.
CREATE OR REPLACE PROCEDURE emp_salup(
p_deptno IN NUMBER,
p_salup IN NUMBER
)
IS
BEGIN
UPDATE emp
SET sal = sal + sal * (p_salup/100)
WHERE deptno = p_deptno;
dbms_output.put_line(p_deptno ||'번 부서의 직원들의 급여가 ' || p_salup ||'% 만큼 올랐습니다.');
END;
/
------------------------------------------------------------
SELECT deptno, ename, sal FROM emp ORDER BY deptno;
EXEC emp_salup(10, 10); --10번 부서 직원들의 급여 10% 인상
SELECT deptno, ename, sal FROM emp ORDER BY deptno;

PL/SQL 변수 종류
- 일반 변수
count NUMBER();
emp_name VARCHAR2(10);
- 상수: CONSTANT 키워드 사용 (변경 불가)
count CONSTANT NUMBER();
emp_name CONSTANT VARCHAR2(10);
- %TYPE: 테이블 열 1개의 데이터 형식에 접근
emp_name EMPLOYEES.EMPLOYEE_ID%TYPE --employees테이블의 employee_id와 같은 데이터타입
emp_email EMPLOYEES.EMAIL%TYPE --employees테이블의 email과 같은 데이터타입
- %ROWTYPE: 테이블 전체 열의 데이터 형식에 접근
emp EMPLOYEES%ROWTYPE --employees테이블 전체 열의 데이터 형식에 접근
dept DEPARTMENT%ROWTYPE --department테이블 전체 열의 데이터 형식에 접근
- 레코드(Record): 여러 개의 열의 데이터 형식을 지정
TYPE user_type IS RECORD (name VARCHAR2(10), email VARCHAR2(20));
user user_type;
- 컬렉션(Collection): 배열(Array)과 유사하며, VARRAY, 중첩 테이블(Nested Table), 연관 배열(Associative Array) 등이 있음
--1. VARRAY
TYPE v_array_type IS VARRAY(5) OF NUMBER(10);
--2. Nested Table(중첩 테이블)
TYPE nest_tbl_type IS TABLE OF VARCHAR2(10);
nest_tbl test_tbl_type;
--3. Associative Array(연관 배열)
TYPE a_array_type IS TABLE OF NUMBER(10) INDEX BY VARCHAR2(10);
a_array a_array_type;
1. %TYPE
CREATE OR REPLACE PROCEDURE emp_info(
p_empno IN EMP.EMPNO%TYPE --emp테이블의 empno와 같은 데이터타입
)
IS
vname EMP.ENAME%TYPE; --emp테이블의 ename과 같은 데이터타입
vjob EMP.JOB%TYPE; --emp테이블의 job과 같은 데이터타입
vsal EMP.SAL%TYPE; --emp테이블의 sal과 같은 데이터타입
BEGIN
SELECT ename, job, sal
INTO vname, vjob, vsal
FROM emp
WHERE empno = p_empno;
dbms_output.put_line('사번: ' || p_empno);
dbms_output.put_line('사원명: ' || vname);
dbms_output.put_line('업무: ' || vjob);
dbms_output.put_line('급여: ' || vsal);
EXCEPTION WHEN no_data_found THEN
dbms_output.put_line(p_empno || '번 사번을 가진 사원은 존재하지 않습니다.');
END;
/
----------------------------------------------------------------
EXECUTE emp_info(7000); --없음
EXECUTE emp_info(7369); --있음

변수명 테이블명.컬럼명%TYPE;
→ 해당 변수명은 지정한 테이블 컬럼의 데이터 타입, 크기를 따라가게 된다.
%TYPE은 한번 설정해 두면 테이블 컬럼의 데이터 타입과 크기가 변경되어도 신경 쓸 필요가 없어진다.
2. %ROWTYPE
--상품번호를 in 파라미터로 전달하면 해당 상품정보(상품명, 판매가, 배송비)를
--가져와 출력하는 프로시저 작성
CREATE OR REPLACE PROCEDURE prod_info(
pno IN PRODUCTS.PNUM%TYPE
)
IS
vprod PRODUCTS%ROWTYPE;
BEGIN
SELECT products_name, output_price, trans_cost
INTO vprod.products_name, vprod.output_price, vprod.trans_cost
FROM products
WHERE pnum = pno;
dbms_output.put_line('상품명: ' || vprod.products_name|| ', 판매가: ' ||
vprod.output_price || ', 배송비: ' || vprod.trans_cost);
EXCEPTION WHEN no_data_found THEN
dbms_output.put_line(pno || '번은 없는 상품입니다.');
END;
/
EXEC prod_info(10); --있음
EXEC prod_info(11); --없음
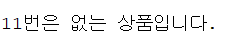
변수명 테이블명%ROWTYPE;
→ 변수명에 테이블에 들어있는 컬럼들을 담고
SELECT시 INTO 절에 테이블명.변수명으로 값을 넣어 사용하게 되는데
이렇게 하면 변수 하나만 생성해도 원하는 테이블 전체의 컬럼을 선택할 수 있고
나중에 테이블을 변경하더라도 PL/SQL에서는 변경할 게 없다.
테이블을 자주 변경하는 경우에는
%TYPE, %ROWTYPE을 활용하는 것이 좋다.
3. Collection - 연관 배열(Associative Array)
--3. Associative Array(연관 배열)
--저장할 테이블 선언
TYPE a_array_type IS TABLE OF NUMBER(10) INDEX BY VARCHAR2(10);
--테이블 타입의 변수 선언
a_array a_array_type;
1. 저장할 테이블 선언
TYPE 테이블타입명 IS TABLE OF 컬럼자료형 INDEX BY BINARY_INTEGER;
--INTEGER유형의 index를 사용하겠다
2. 테이블 타입의 변수 선언
변수명 테이블타입명;
변수명 BINARY_INTEGER := 초기값;
오라클 FOR문
FOR 증감변수 IN 초기값..최종값
LOOP
처리문;
END LOOP;
--[실습] 부서번호를 인 파라미터로 전달하면 해당 부서의 사원명, 담당업무를 가져와 출력
CREATE OR REPLACE PROCEDURE table_type(pno IN emp.deptno%TYPE)
IS
--ename을 저장할 테이블 선언
TYPE ename_arr_type IS TABLE OF emp.ename%TYPE
INDEX BY BINARY_INTEGER;
--job을 저장할 테이블 선언
TYPE job_arr_type IS TABLE OF emp.job%TYPE
INDEX BY BINARY_INTEGER;
--테이블 타입의 변수 선언
ename_arr ename_arr_type;
job_arr job_arr_type;
i BINARY_INTEGER := 0; --index의 초기값을 0으로 지정
BEGIN
FOR k IN (SELECT ename, job FROM emp WHERE deptno = pno)
--k에 SELECT 쿼리를 실행한 테이블 데이터 저장
LOOP
i := i + 1; --i값 증가 (오라클은 인덱스가 1부터 시작함)
--테이블 타입 변수에 결과값 저장
ename_arr(i) := k.ename; --ename_arr에 ename컬럼의 데이터를 한 행씩 출력
job_arr(i) := k.job; --job_arr에 job컬럼의 데이터를 한 행씩 출력
END LOOP;
--저장된 값 출력
FOR j IN 1..i
LOOP
dbms_output.put_line('사원명: ' || ename_arr(j) || ', 업무: ' || job_arr(j));
END LOOP;
END;
/
EXECUTE table_type(30); --30번 부서 사원들 출력
4. 레코드(Record)
여러 개의 열의 데이터 형식을 지정
TYPE user_type IS RECORD (name VARCHAR2(10), email VARCHAR2(20));
user user_type;1. 저장할 레코드 선언
TYPE 레코드타입명 IS RECORD (
필드명1 자료형,
필드명2 자료형, ...
)
2. 레코드 타입의 변수 선언
변수명 레코드타입명;
--[실습] 게시판(BBS)의 작성자명을 인 파라미터로 전달하면 해당 작성자가 쓴 글을 가져와 출력
CREATE OR REPLACE PROCEDURE rec_type (pname IN BBS.WRITER%TYPE)
IS
--저장할 레코드 선언
TYPE bbs_type IS RECORD(
vno BBS.NO%TYPE,
vtitle BBS.TITLE%TYPE,
vwriter BBS.WRITER%TYPE,
vcontent BBS.CONTENT%TYPE,
vwdate BBS.WDATE%TYPE
);
--레코드 타입의 변수 선언
vbbs bbs_type;
BEGIN
SELECT * INTO vbbs FROM bbs WHERE writer = pname;
dbms_output.put_line(vbbs.vno || ' ' || vbbs.vtitle|| ' '
|| vbbs.vwriter || ' ' || vbbs.vcontent || ' '
|| vbbs.vwdate);
--예외처리
EXCEPTION
WHEN no_data_found
THEN dbms_output.put_line(pname || '님의 글은 없습니다');
WHEN too_many_rows
THEN dbms_output.put_line(pname || '님의 글은 2건 이상입니다');
WHEN OTHERS
THEN dbms_output.put_line('기타 에러 발생');
END;
/
EXEC rec_type('lee');
EXEC rec_type('seo'); --no_data_found
EXEC rec_type('kim'); --too_many_rows

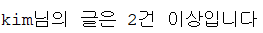
레코드(Record)는 여러 행을 처리하지 못한다. 여러 행을 처리하기 위해서는 CURSOR(커서)를 사용해야 한다.